
|
|
Программирование >> Составные структуры данных
РИСУНОК 1.6 ПРИМЕР БЫСТРОГО ОБЪЕДИНЕНИЯ (НЕ ОЧЕНЬ БЫСТРОГО ПОИСКА) Здесь изображено содержимое массива id после обработки каждой из показанных слева пар алгоритмом быстрого поиска (программа 1.1). Затененные записи - те, которые изменяются для выполнения операции объединения (только по одной для каждой операции). При обработке парыр q мы следуем указателям, указывающим изр, чтобы добраться до записи i, у которой idfij == /; затем мы следуем указателям, исходящим из q, чтобы добраться до записи j, у которой id[j] ==j; затем, если i и j рагтичны, мы устанавливаем idfiJ = id[/J Для выполнения операции find для пары 5-8 (последняя строка) i принимает значения 5 6 9 01, aj - значения 801. pq 0123456789 34 01244S6789 49 0124956789 80 0124956709 23 0194956709 56 0194966709 29 0194966709 59 0194969709 73 C1949S9S09 48 0194969S00 56 0194969900 02 0194969S00 61 1194969S00 58 1194969900 А пока быстрое объединение можно считать усовершенствованием, поскольку оно устраняет основной недостаток быстрого поиска (тот, что для выполнения М операций union между N объектами программе требуется выполнение, по меньшей мере, Л М инструкций). Программа 1.2 Решение задачи связности методом быарого объединения Если тело цикла while в программе 1.1 заменить этим кодом, мы получим программу, которая соответствует тем же спецификациям, что и программа 1.1, но выполняет меньше вычислений для операции union за счет выполнения большего количества вычислений для операции find. Циклы for и последующий оператор if в этом коде определяют необходимые и достаточные условия для того, чтобы массив id для р и q был связанным. Оператор присваивания id[i] = j реализует операцию union. for (i = р; for (j = q; if -(i == j) id[i] = j; cout i != id[i] j != id[j] continue; p i = id[i]) j = id[j]) q endl; Это различие между быстрым объединением и быстрым поиском действительно является усовершенствованием, но быстрое объединение все же обладает тем недостатком, что нельзя гарантировать, что оно будет выполняться существенно быстрее быстрого поиска в каждом случае, поскольку характер вводимых данных может замедлять операцию find. Лемма 1.2 При наличии М пар N объектов, когда М > N, для решения задачи связности алгоритму быстрого объединения может потребоваться выполнение более чем М N/ 2 инструкций. Предположим, что пары вводятся в следующем порядке: 1-2, 2-3, 3-4 и т.д. После ввода 7V- 1 таких пар мы имеем Л объектов, принадлежащих к одному набору, и сформированное алгоритмом быстрого объединения дерево представляет собой прямую линию, где объект Л указывает на объект 7V- 1, тот, в свою очередь, - на объект Л - 2, тот - на Л - 3 и т.д. Чтобы выполнить операцию find для объекта Л, программа должна отследить Л- 1 указатель. Таким образом, среднее количество указателей, отслеживаемых для первых N пар, равно (0+ 1 +...+ (N-I))/ N= (TV- 1)/2 Теперь предположим, что все остальные пары связывают объект с каким-либо другим объектом. Чтобы выполнить операцию fmd для каждой из этих пар, требуется отследить, по меньшей мере, (Л- 1) указатель. Общая сумма для М операций find для этой последовательности вводимых пар определенно больше MNI 2. К счастью, можно легко модифицировать алгоритм, чтобы худшие случаи, подобные этому, гарантированно не имели места. Вместо того чтобы произвольным образом соединять второе дерево с первым для выполнения операции union, можно отслеживать количество узлов в каждом дереве и всегда соединять меньшее дерево с большим. Это изменение требует несколько более объемного кода и наличия еще одного массива для хранения счетчиков узлов, как показано в программе 1.3, но оно ведет к существенному повышению эффективности. Мы будем называть этот алгоритм алгоритмом взвешенного быстрого объединения (weighted quick-union algorithm). Программа 1.3 Взвешенная версия быстрого бъединения Эта программа - модификация алгоритма быстрого объединения (см. программу 1.2), которая в служебных целях для каждого объекта, у которого id[i] == i, поддерживает дополнительный массив sz, представляющий собой массив количества узлов в соответствующем дереве, чтобы операция union могла связывать меньшее из двух указанных деревьев с большим, тем самым предотвращая разрастание длинных путей в деревьях. #include <iostream.h> static const int N = 10000; int main() { int i, j, p, q, id[N] , sz [N] ; for (i = 0; i < N; i++) { id[i] = i; sz[i] = 1; } while (cin p q) for (i = p; i != id[i]; i = id[i]); for (j = q; j != id[j]; j = id[j]); continue; sz[j]) { id[i] = j; sz[j] += s2[i] ; } else { id[j] = i; sz[i] += sz[j]; } cout p q endl; if (i == j) if (sz[i] < ® (D (D ® CD CD © (D (D ® ®®®@(D(D(7)(8) ®® ®ф@ ® ®®® D® ill ®®® 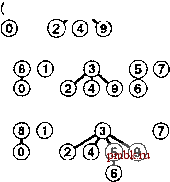 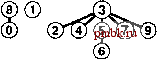 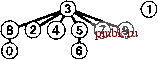 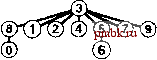 РИСУНОК 1.7 ПРЕДСТАВЛЕНИЕ ВЗВЕШЕННОГО БЫСТРОГО ОБЪЕДИНЕНИЯ В ВИДЕ ДЕРЕВА На этой последовательности рисунков демонстрируется результат изменения алгоритма быстрого объединения для связывания корня меньшего из двух деревьев с корнем большего из деревьев. Расстояние от каждого узла до корня его дерева не велико, поэтому операция поиска выполняется эффективно. На рис. 1.7 показан бор деревьев, созданных алгоритмом взвешенного поиска для примера ввода, приведенного на рис. 1.1. Даже в этом небольшом примере пути в деревьях существенно короче, чем в случае невзвешенной версии, показанной на рис. 1.5. Рисунок 1.8 иллюстрирует, что происходит в худшем случае, когда размеры наборов, которые должны быть объединены в операции union, всегда равны (и являются степенью 2). Эти структуры деревьев выглядят сложными, но они характеризуются простым свойством, что максимальное количество указателей, которые необходимо отследить, чтобы добраться до корня в дереве, состоящем из 2 узлов, равно п. Более того, при слиянии двух деревьев, состоящих из 2 узлов, мы получаем дерево, состоящее из 2 узлов, а максимальное расстояние до корня увеличивается до и + 1. Это наблюдение можно обобщить для доказательства того, что взвешенный алгоритм значительно эффективнее невзвешенного. Лемма 1.3 Для определения того, связаны ли два из N объектов, алгоритму взвешенного быстрого объединения требуется отследить максимум Ig TV указателей. Можно доказать, что для операции union сохраняется свойство, что количество указателей, отслеживаемых из любого узла до корня в наборе к объектов, не превышает Ig к. При объединении набора, состоящего из / узлов, с набором, состоящим из j узлов, при / < j количество указателей, которые должны отслеживаться в меньшем наборе, увеличивается на 1, но теперь узлы находятся в наборе размера / + у, и, следовательно, свойство остается справедливым, поскольку 1 + Ig / = lg(/ + /) < lg(/ + j). @ @ (3) (D (D ® (7) ® (9) ®@® ® ® (7)® ® Ф ® ® ®®® (7)® ® CO ® (5)  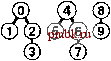 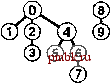 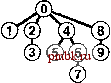 РИСУНОК 1.8 ВЗВЕШЕННОЕ БЫСТРОЕ ОБЪЕДИНЕНИЕ {ХУДШИЙ СЛУЧАЙ) Наихудший сценарий для алгоритма взвешенного быстрого объединения - когда каждая операция объединения связывает деревья одинакового размера. Если количество объектов меньше 2 , расстояние от любого узла до корня его дерева меньше п. Практическое следствие леммы 1.3 заключается в том, что количество инструкций, которые алгоритм взвешенного быстрого объединения использует для обработки М ребер между N объектами, не превышает М Ig TV, умноженного на некоторую константу (см. упражнение 1.9). Этот вывод резко отличается от вывода, что алгоритм быстрого поиска всегда (а алгоритм быстрого объединения иногда) использует не менее MN/2 инструкций. Таким образом, при использовании взвешенного быстрого объединения можно гарантировать
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.004
При копировании материалов приветствуются ссылки. |