
|
|
Программирование >> Составные структуры данных
объекты р и q связаны. Для простоты N определенв как константа времени компиляции. Иначе можно было бы считывать ее из ввода и распределять массив id динамически (см. раздел 3.2). #include <iostreain.h> static const int N = 10000; int mainO { int i, p, q, id[N]; for (i = 0; i < N; i++) id[i] = i; while (cin p q) { int t = id[p] ; if (t == id[q]) continue; for (i = 0; i < N; i++) if (id[i] == t) id[i] = id[q]; cout p q endl; Изменения массива при выполнении операций union в примере из рис. 1.1 показаны на рис. 1.3. Для реализации операции У/лй достаточно проверить указанные записи массива на предмет равенства - отсюда и название быстрый поиск (quick-find). С другой стороны, операция union требует просмотра всего массива для каждой вводимой пары. Лемма 1.1 Алгоритм быстрого поиска выполняет не менее М N инструкций для решения задачи связности при наличии N объектов, для которых требуется выполнение М операций объединения. 0123456789 Для каждой из М операций union цикл for выполняется раз. Для каждой итерации требуется выполнение, по меньшей мере, одной инструкции (если только проверять, завершился ли цикл). На современных компьютерах можно выполнять десятки или сотни миллионов инструкций в секунду, поэтому эти затраты не заметны, если значения М и N малы, но в современных приложениях может потребоваться обработка миллиардов объектов и миллионов вводимых пар. Поэтому мы неизбежно приходим к заключению, что подобную проблему нельзя решить приемлемым образом, используя алгоритм быстрого поиска (см. упражнение 1.10). Строгое обоснование этого заключения приведено в главе 2. Графическое представление массива, показанного на рис. 1.3, приведено на рис. 1.4. Можно считать, что некоторые объекты представляют набор, к которому они принадлежат, а остальные указывают на представителя их набора. Причина обращения к этому графическому представлению массива вскоре станет понятна. Обратите внимание, что связи между > ьектами в этом представлении не обязательно со- 3 4 8 2 5 2 5 7 4 5 О б О О О О О О О О О О О 1 РИСУНОК 1.3 ПРИМЕР БЫСТРОГО ПОИСКА (МЕДЛЕННОГО ОБЪЕДИНЕНИЯ) Здесь изображено содержимое массива id после того, как каждая пара, приведенная слева, обрабатывается алгоритмом быстрого поиска (программа 1.1). Затененные записи - те, которые изменяются для выполнения операции union. При обработке пары р q все записи со значением idfpj изменяются на содержащие значение idfqj. ® Ф @ ® ® ® ® (8) (9) :9) ®®®® [3) С4) (3) C4J Ф® (9 (2)(3) W ответствует связям во вводимых парах - они представляют собой информацию, запоминаемую алгоритмом, чтобы иметь возможность определить, соединены ли пары, которые будут вводиться в будущем. Следующий алгоритм, который мы рассмотрим - метод дополнительный к пред-ществующему, названный алгоритмом быстрого объединения. В его основе лежит та же структура данных - индексированный по именам объектов массив - но в нем используется иная интерпретация значений, что приводит к более сложной абстрактной структуре. Каждый объект указывает на другой объект в этом же наборе, структуре, которая не содержит циклов. Для определения того, находятся ли два объекта в одном наборе, мы следуем указателям для каждого из них до тех пор, пока не будет достигнут объект, который указывает на самого себя. Объекты находятся одном наборе тогда и только тогда, когда этот процесс приводит их к одному и тому же объекту. Если они не находятся в одном наборе, процесс завершится на других объектах (которые указывают на себя). Тогда для образования объединения достаточно связать один объект с другим, чтобы выполнить операцию union; отсюда и название быстрое объединение (quick-union). На рис. 1.5 показано графическое представление, которое соответствует рис. 1.4 при выполнении алгоритма быстрого объединения к массиву, изображенному на рис. 1.1, а на рис. 1.6 показаны соответствующие изменения в массиве id. Графическое представление структуры данных позволяет сравнительно легко понять действие алгоритма - вводимые пары, которые заведомо должны быть соединены в данных, связываются одна с другой и в структуре данных. Как упоминалось ранее, важно отметить, что связи в структуре данных не обязательно совпадают со связями в приложении, обусловленными вводимыми парами; вместо этого они конструируются алгоритмом так, чтобы обеспечить эффективную реализацию операций union и find. Связанные компоненты, изображенные на рис. 1.5, называются деревьями (tree); это основополагающие комбинационные структуры, которые многократно встречаются в книге. Свойства деревьев будут подробно рассмотрены в главе 5. Деревья, изображенные на рис. 1.5, удобны для выполнения операций union и find, поскольку их можно быстро построить, и они характеризуются тем, что два (2) (3) (4) ® ® ®® ® ® ® ® ® 6)® ® ® (2743. 57Тб) (0ГГ2ПЗГС4 РИСУНОК 1.4 ПРЕДСТАВЛЕНИЕ БЫСТРОГО ПОИСКА В ВИДЕ ДЕРЕВА На этом рисунке показано графическое представление примера, приведенного на рис. 1.3. Связи на этом рисунке не обязательно представляют связи в массиве ввода. Например, структура, показанная на нижнем рисунке, содержит связь 1-7, которая отсутствует во вводе, но образуется в результате строки связей 7-3-4-9-5-6-1. объекта связаны в дереве тогда и только тогда, когда объекты связаны в массиве ввода. Перемещаясь вверх по дереву, можно легко отыскать корень дерева, содержащего каждый объект, и, следовательно, можно выяснить, связаны они или нет. Каждое дерево содержит только один объект, указывающий сам на себя, называемый корнем дерева. Указатель на себя на диаграммах не показан. Начав с любого объекта дерева и перемещаясь к объекту, на который он указывает, затем следующему указанному объекту и т.д., мы всегда со временем попадаем к корню. Справедливость этого свойства можно доказать методом индукции: это справедливо после инициализации массива так, чтобы каждый объект указывал на себя, и если это справедливо перед выполнением данной операции union, это безусловно справедливо и после нее. Диаграммы для алгоритма быстрого поиска, показанные на рис. 1.4, характеризуются теми же свойствами, которые описаны в предыдущем абзаце. Различие состоит в том, что в деревьях быстрого поиска мы достигаем корня из всех узлов, следуя лишь одной связи, в то время как в дереве быстрого объединения для достижения корня может потребоваться проследовать по нескольким связям. Профамма 1.2 - реализация операций union и find, образующих алгоритм быстрого объединения для решения задачи связности. На первый взгляд кажется, что алгоритм быстрого объединения работает быстрее алгоритма быстрого поиска, поскольку для каждой вводимой пары ему не нужно просматривать весь массив; но на сколько быстрее? В данном случае ответить на этот вопрос труднее, чем в случае быстрого поиска, поскольку время выполнения в большей степени зависит от характера ввода. Выполнив экспериментальные исследования или математический анализ (см. главу 2), можно убедиться, что программа 1.2 значительно эффективнее программы 1.1 и ее можно использовать для решения очень сложных реальных задач. Одно из таких экспериментальных исследований будет рассмотрено в конце этого раздела. ® ф © ® ® (6) (7) ® ® ® ®Ф@®®®®® ® ®@®®®®® ® (8J 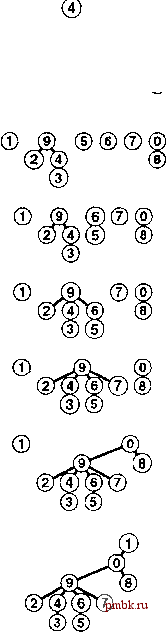 РИСУНОК 1.5 ПРЕДСТАВЛЕНИЕ БЫСТРОГО ОБЪЕДИНЕНИЯ В ВИДЕ ДЕРЕВА Этот рисунок - графическое представление примера, показанного на рис. 1.3. Мы прочерчиваем линию от объекта i к объекту idfij.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |